Public repository for spaMM
What is spaMM ?
spaMM is an R package originally designed for fitting spatial generalized linear Mixed Models, particularly the so-called geostatistical model allowing prediction in continuous space. But it is now a more general-purpose package for fitting mixed models, spatial or not, and with efficient methods for both geostatistical and autoregressive models. Several non-GLM response families are now handled. It can fit multivariate-response models, including some of interest in quantitative genetics or species-distribution modeling. It can also fit models with non-gaussian random effects (e.g., Beta- or Gamma-distributed), structured dispersion models (including residual dispersion models with random effects), and implements several variants of Laplace and PQL approximations, including (but not limited to) those discussed in the h-likelihood literature (see References).
What to look for (or not) here ?
This repository provides whatever information I do not try to put into the R package, such as its vignette-like gentle introduction (latest version: 2023/08/30) and the slides from the presentation of spaMM at the useR2021 conference.
It might also be used to distribute development versions of spaMM. However, use a CRAN repository for standard installation of the package, and see the (unofficial) CRAN github repository for an archive of sources for all versions of spaMM previously published on CRAN.
General features of spaMM
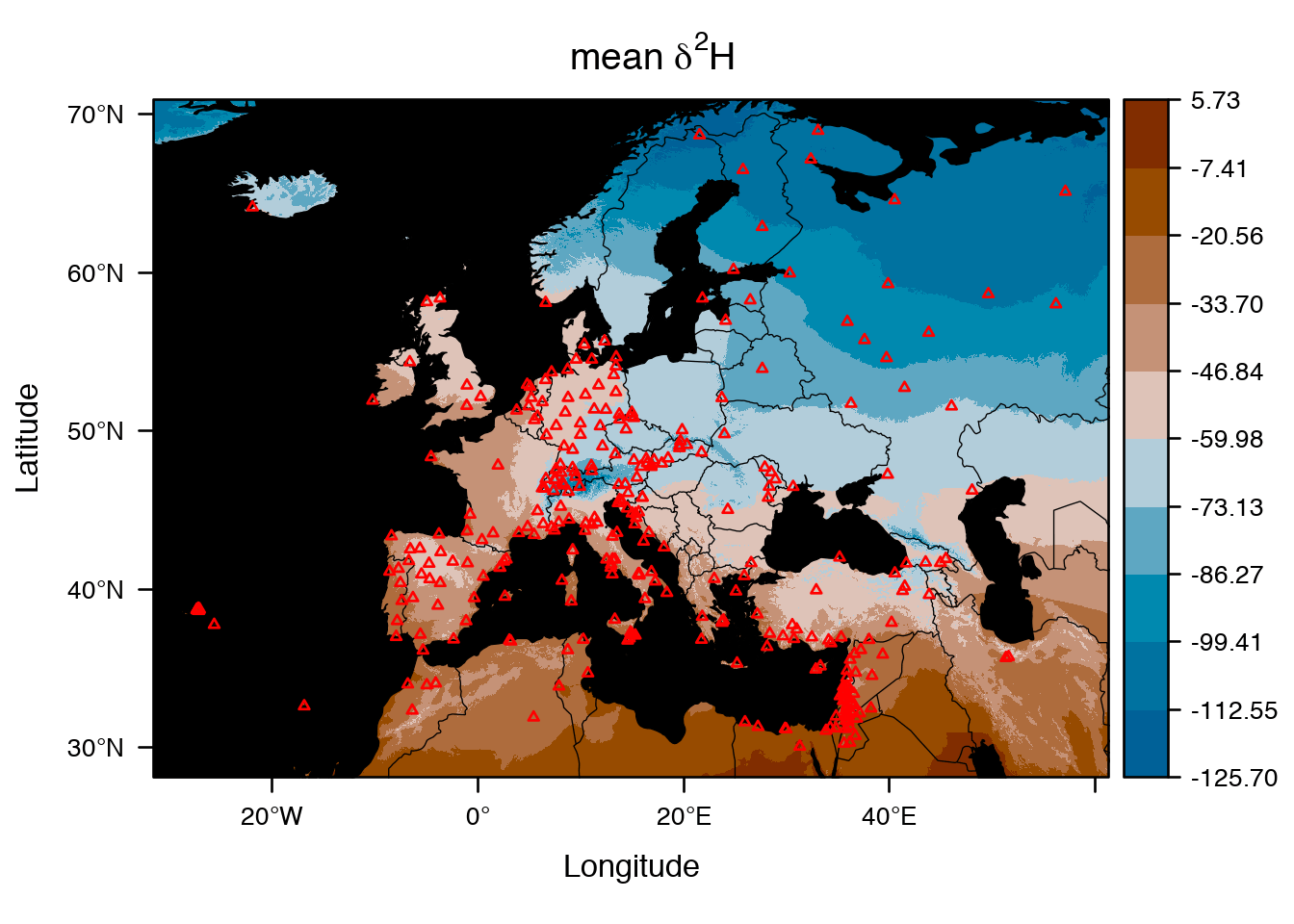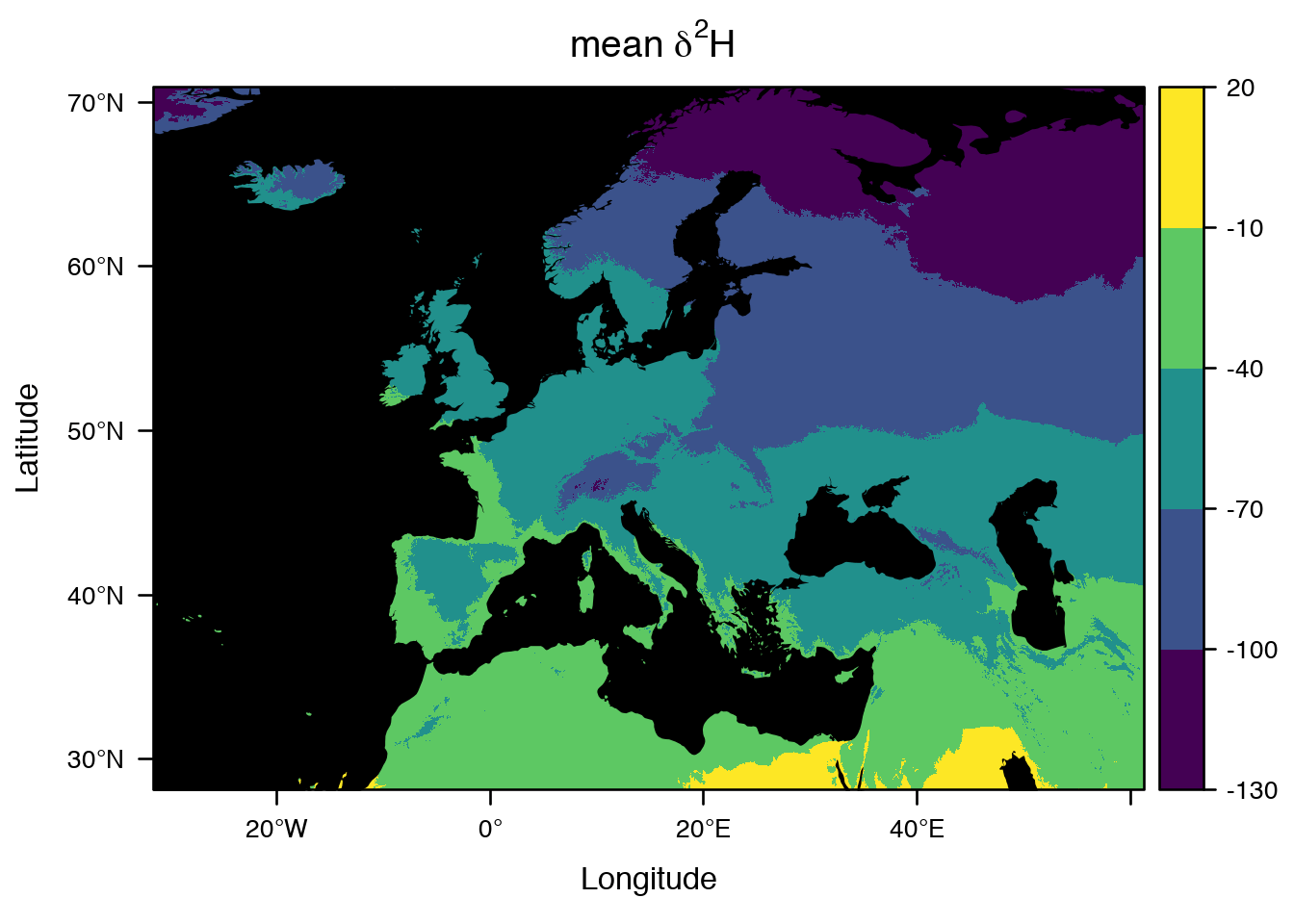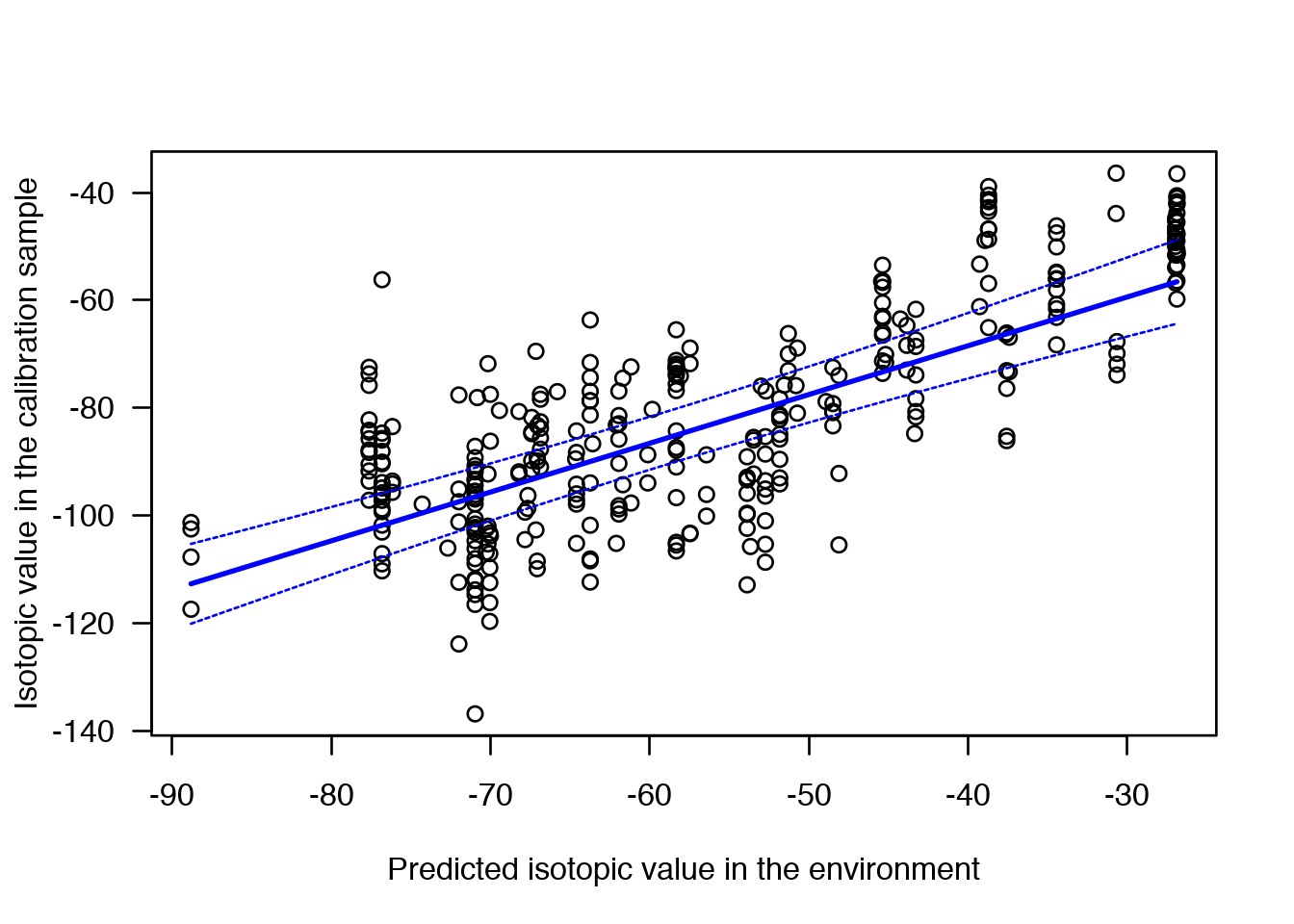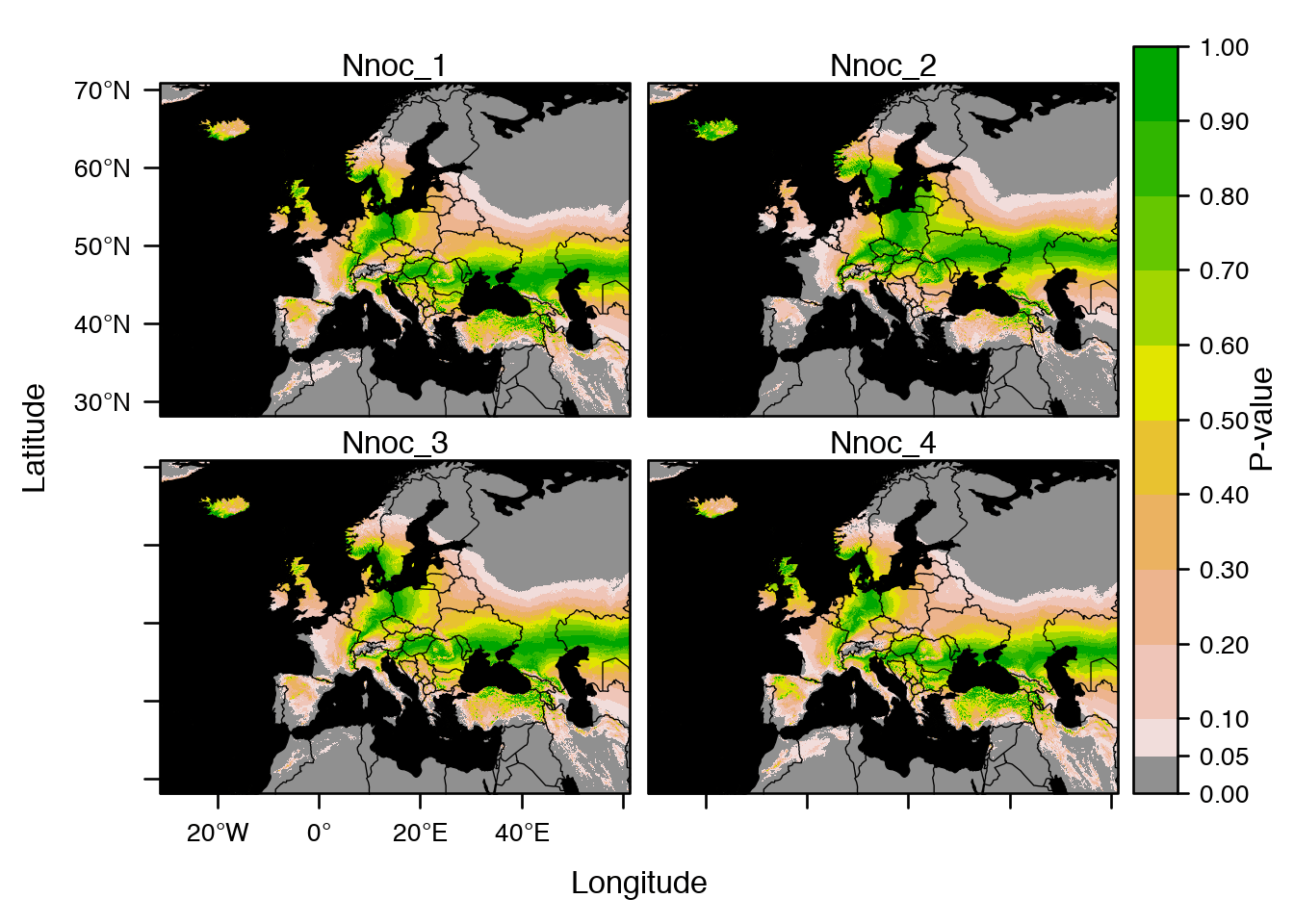
The spaMM package was developed first to fit mixed-effect models with spatial correlations, which commonly occur in ecology, but it has since been developed into a more general package for inferences under models with or without spatially-correlated random effects, including multivariate-response models. To make it competitive to fit large data sets, spaMM has distinct algorithms for three cases: sparse precision, sparse correlation, and dense correlation matrices, and is efficient to fit geostatistical, autoregressive, and other mixed models on large data sets. Notable features include:
- Fitting spatial and non-spatial correlation models: geostatistical models with random-effect terms following the
Maternas well as the much less knownCauchycorrelation models, autoregressive models described by anadjacencymatrix, AR(p) and ARMA(p,q) time-series models (ARpandARMA), or an arbitrary given precision or correlation matrix (corrMatrix). Conditional spatial effects can be fitted, as in (say)Matern(female|...) + Matern(male|...)to fit distinct random effects for females and males (e.g., Tonnabel et al., 2021). "Composite" random effects that combine features of such autocorrelated random effects and of random-coefficient models (say,Matern(age|...)) can be fitted. Brave users can even define their own parametric correlation models, to be fitted as any other random effect (thecorrFamilyfeature). - A further class of spatial correlation models, "Interpolated Markov Random Fields" (
IMRF) covers widely publicized approximations of Matérn models (Lindgren et al. 2011) and the multiresolution model of Nychka et al. 2015. - Symmetric and antisymmetric dyadic interaction effects (such as considered in so-called Bradley-Terry models or in diallel experiments) can be fitted as fixed or as random effects (see e.g.
X.antisym,diallelorantisymdocumentations) - Allowed response families include beta response, beta-binomial, the Conway-Maxwell-Poisson (
COMPoisson), and two negative binomial families. Zero-truncated variants of thepoissonand negative-binomial families are handled; - All the above features combined in multivariate-response models, including random effects correlated over different response variables;
- ML and REML fits (see below for comments on likelihood approximations);
- A replacement function for
glm, useful when the latter (or evenglm2) fails to fit a model; - A syntax close to that of
glmor [g]lmer. - Many extractor methods similar to those in
statsornlme/lmer, and functions for inference beyond the fits, such asconfint()for confidence intervals of fixed-effect parameters,predict()and related functions for point prediction and prediction variances, and compatibility with functions from other packages such asmultcomp::glht()andlmerTestprocedures providing F tests using Satterthwaite method (see`post-fit`andanovadocumentation items); - Simple facilities for quickly drawing maps from model fits, using only base graphic functions. See here for more elaborate examples of producing maps. The animated graphics on this page is from an application using the
IsoriXpackage.
Installation
Installing spaMM from CRAN is generally straightforward, particularly when installing a compiled version. Installing from source on Windows is also easy when the Rtools have been installed.
Additional steps may be needed on other operating systems, for the required GSL library and nloptr package (which requires the NLopt library, version 2.7), and optionally for the ROI.plugin.glpk package (which requires the Rglpk package, which itself requires the external glpk library)
For Debian or Ubuntu, this should typically work:
sudo apt-get install libgmp3-dev
sudo apt-get install libnlopt-dev
sudo apt-get install libglpk-dev \
If the installation of nloptr or NLopt fails, do read the messages. They may tell you, for example, that NLopt 2.7 is not installed for your system. Further, it may not be available by apt-get for your system. If NLopt 2.7 is not installed, the nloptr installation script tries to compile NLopt 2.7 from source, but for that purpose cmake version 3.15 (or higher) is required, and you need to make sure that it is installed. The cmake installation procedure described here may then be useful.
Mac users may find HomeBrew useful: install it and then run
brew install gsl and brew install glpk. However, my limited experience with it was deceptive. It did not tell
when no writeable /usr/local/include directory existed, preventing the installation of the GSL. The alternative installation procedure described here has then been useful.
Possibly obsolete: once upon a time on Windows I had to \cr
pacman -S mingw-w64-x86_64-nlopt; and
pacman -S mingw-w64-x86_64-glpk in the Rtools40 bash shell, together with\cr
Sys.setenv(GLPK_HOME = "$(MINGW_PREFIX)") in the R session. Previously I had to install glpk from https://sourceforge.net/projects/winglpk/.
The different concerned packages may also provide installation instructions.
References
The performance of likelihood ratio tests based on spaMM fits, and the impact of some likelihood approximations, were assessed for spatial GLMMs in:
Rousset F., Ferdy J.-B. (2014) Testing environmental and genetic effects in the presence of spatial autocorrelation. Ecography, 37: 781-790.
Also available here is the Supplementary Appendix G from that paper, including comparisons with a trick that has been uncritically used to constrain the functions lmer and glmmPQL to analyse spatial models.
For some substantial use of various features of spaMM, see e.g. the IsoriX project, or a story about social dominance in hyaenas, or yet another depressing story about climate change, or the life-history of mothers of twins, or a comparison of prediction by LMMs and by random-forest methods (in supplementary material of a paper on protected area personnel), or analyses of dyadic interactions in mandrills, or comparative analyses by heteroscedastic models with phylogenetic autocorrelation.
Initial development drew inspiration from work by Lee and Nelder on h-likelihood and more elaborate approximations of likelihood (e.g. Lee, Nelder & Pawitan, 2006; Lee & Lee 2012; see also Molas and Lesaffre, 2010). The latter two references, and spaMM itself, may actually be more widely understood as applications of Laplace approximations of likelihood than as applications of a distinctive h-likelihood concept. spaMM retains from Lee & Nelder's work several distinctive features, such as a concept of restricted likelihood applicable beyond LMMs, specific methods to fit models with non-gaussian random effects, structured dispersion models with random effects, and implementation of several variants of Laplace and PQL approximations. However, it has departed from their work in various ways. Notably, the default likelihood and restricted likelihood approximations now go beyond those discussed in these works. For ML fits, it is the same Laplace approximation as in TMB (Kristensen et al., 2016) and packages based on TMB, because TMB and spaMM (with default arguments) use the observed Hessian matrix of ``joint likelihood'' where the h-likelihood literature only considers the expected Hessian matrix. This makes a difference for GLM families with non-canonical link, or for response families not of the GLM class.
Credits
Initial development was supported by a PEPS grant from the CNRS and University of Montpellier.